Le premier estimateur de notre forêt ne sera pas un arbre mais une feuille qui aura pour valeur la moyenne de la variable cible.
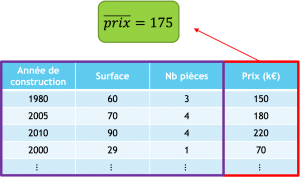
La forêt est pour le moment constituée d’un estimateur qui est la feuille. Les résidus seront donc la différence entre la prédiction de la forêt actuelle et la valeur cible.
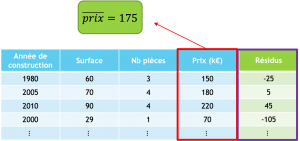
Nous allons entraîner un arbre capable de prédire les résidus d’un exemple en prenant en compte ses variables explicatives.
Une fois l’arbre entraîné il sera ajouté à la forêt. Le but n’est plus de faire la moyenne des estimateurs de notre forêt mais plutôt de compléter les estimateurs déjà présents.
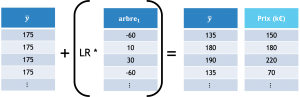
On va donc prendre la prédiction de la feuille et y ajouter la prédiction des résidus de notre premier arbre pondéré par un taux d’apprentissage ou learning rate.
Chaque nouvel arbre de notre forêt aura pour objectif de diminuer le gap entre la prédiction actuelle de la forêt et la valeur cible.