Lorsque l’on demande à des experts de résoudre un problème, il est probable qu’ils ne retournent pas tous la même solution. Cela veut dire que même lorsque l’on fait appel à un expert, on peut toujours s’attendre à une marge d’erreur.
On appelle ce phénomène, la variabilité inter-opérateur.
Il existe une autre source de variabilité lorsque l’on demande à un expert de résoudre un même problème à interval de temps différent. C’est ce que l’on appelle la variabilité intra-opérateur.
Parmi toutes ces réponses, comment savoir laquelle est la bonne ?
La réponse de l’expert 3 ?
la deuxième réponse de l’expert 1 ?
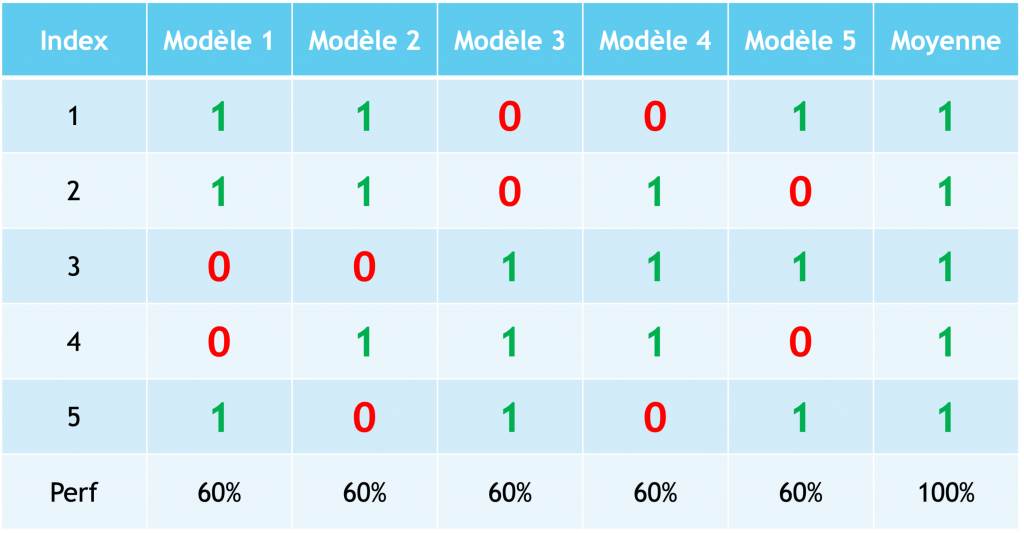
On ne sait pas vraiment, mais ce que l’on peut faire c’est prendre en compte toutes ces réponses en même temps. Dans le cas général, la moyenne des réponses des experts sera plus précise que les réponses indépendantes, c’est ce que l’on appelle la sagesse des foules.
La sagesse des foules est une théorie qui présuppose que la perception et la résolution d’un problème sont plus efficaces par une foule que par n’importe quel individu.
Selon ce concept, une foule d’amateur peut mieux répondre à un problème qu’un expert du domaine.
La foule cependant doit répondre à trois hypothèses pour valider cette théorie :
- la diversité : avoir des personnes de divers milieux avec des idées originales ;
- l’indépendance : permettre à ces avis divers de s’exprimer sans aucune influence ;
- la décentralisation : laisser ces différents jugements s’additionner plutôt que de laisser une autorité supérieure choisir les idées qu’elle préfère.
De ce concept philosophique on en retire une application mathématique : l’ensemble learning.
Les méthodes d’ensemble learning utilisent plusieurs algorithmes d’apprentissage et prennent en compte les résultats de ces modèles afin d’obtenir de meilleures performances prédictives que les modèles pris séparément.